

员工数据练习
基于MySQL 5.7环境

(图片来源网络,侵删)
数据介绍
员工信息表emp
字段:员工id,员工名字,工作岗位,部门经理,受雇日期,薪水,奖金,部门编号
英文名:emp_no,ename,job,mgr,hire_date,sal,bonus,dept_no
 (图片来源网络,侵删)
(图片来源网络,侵删)部门信息表dept
字段:部门编号,部门名称,部门地点
英文名:dept_no,dept_name,dept_addr
问题:
一:基于数据结构编写每张表建表语句
create table emp{ emp_no int ,ename varchar(255) ,job varchar(255) ,mgr int ,hire_date date ,sal int ,bonus int ,dept_no int } create table dept{ dept_no int ,dept_name varchar(255) ,dept_addr varchar(255) }二:将下列数据加载到MySQL中
- 员工数据:
7369,SMITH,CLERK,7902,1980-12-17,800,null,20 7499,ALLEN,SALESMAN,7698,1981-02-20,1600,300,30 7521,WARD,SALESMAN,7698,1981-02-22,1250,500,30 7566,JONES,MANAGER,7839,1981-04-02,2975,null,20, 7654,MARTIN,SALESMAN,7698,1981-09-28,1250,1400,30 7698,BLAKE,MANAGER,7839,1981-05-01,2850,null,30 7782,CLARK,MANAGER,7839,1981-06-09,2450,null,10 7788,SCOTT,ANALYST,7566,1987-04-19,3000,null,20 7839,KING,PRESIDENT,null,1981-11-17,5000,null,10 7844,TURNER,SALESMAN,7698,1981-09-08,1500,0,30 7876,ADAMS,CLERK,7788,1987-05-23,1100,null,20 7900,JAMES,CLERK,7698,1981-12-03,950,null,30 7902,FORD,ANALYST,7566,1981-12-03,3000,null,20 7934,MILLER,CLERK,7782,1982-01-23,1300,null,10
- 部门数据:
10,ACCOUNTING,NEW YORK 10,ACCOUNTING,shanghai 20,RESEARCH,DALLAS 30,SALES,CHICAGO 40,OPERATIONS,BOSTON
三、使用SQL完成下面需求
薪水 = SAL
薪金 = 12*SAL加奖金
年工资 = 年薪 = 12*SAL
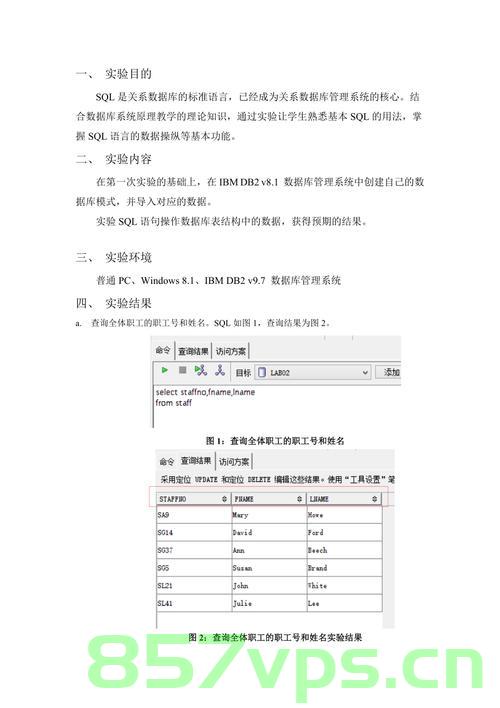
1. 列出至少有一个员工的所有部门。
-- 做关联 select t2.*,t1.counts from( (select dept_no,count(*) as counts from emp group by dept_no) t1 join (select dept_no,dept_name from dept group by dept_no,dept_name) t2 --注: select dept_no,dept_name from dept group by dept_no,dept_name(消除元组重复值) 、select dept_no,dept_name from dept区别 on t1.dept_no=t2.dept_no );2. 列出薪金比“SMITH”多的所有员工。
select *,sal*12+bonus as money from emp WHERE sal*12+bonus > ( SELECT sal*12+bonus FROM emp WHERE ename='SMITH')
3. 列出所有员工的姓名及其直接上级的姓名。
-- 将两个完整的表关联后再进行取值 select t1.ename,t2.ename bossname from (select * from emp) t1 -- left join 可取到老板 left join (select * from emp) t2 on t1.mgr=t2.emp_no;
4. 列出受雇日期早于其直接上级的所有员工。
select t1.ename,t1.hire_date from (select * from emp) t1 join (select * from emp) t2类似上题,即在连接时再加一个判断 on t1.mgr=t2.emp_no and t1.hire_date
5. 列出部门名称和这些部门的员工信息,同时列出那些没有员工的部门。
select t1.ename,t2.* from( (select dept_no,ename from emp) t1 -- 右连接,右侧的表中的数据项,左侧表中有则保留、无则填NULL(仍旧保留) right join (select dept_no,dept_name from dept group by dept_no,dept_name) t2 on t1.dept_no=t2.dept_no );6. 列出所有“CLERK”(办事员)的姓名及其部门名称。
select t1.ename,t2.dept_name from (select * from emp where job="CLERK") t1 join -- 注: 该步骤中加入了group by,其作用是防止左表中的最后一条数据与右表中的前两条数据都成功匹配,从而使合成表中出现重复值 (select dept_name,dept_no from dept group by dept_name,dept_no) t2 on t1.dept_no=t2.dept_no; -- 注:select * from dept group by dept_name,dept_no,其中的“*”出错,不可这样查询
7. 列出最低薪水大于1500的各种工作。
-- 先用第一个group by找出所有工资大于1500的人的工作名称和工资,拿到了一个有着重复工作名称的表。第二个group by用来将工作名称去重 select job from (select job,sal from emp GROUP BY job,sal having sal > 1500) t1 GROUP BY job;
8. 列出在部门“SALES”(销售部)工作的员工的姓名,假定不知道销售部的部门编号
-- ???假定不知道销售部的部门编号(不知道也没关系,我又不取该值) select t1.ename,t2.dept_name from (select * from emp) t1 join (select * from dept where dept_name="SALES") t2 on t1.dept_no=t2.dept_no;
9. 列出薪金高于公司平均薪金的所有员工。
-- 薪金 = 12*SAL加奖金 , select avg(sal*12) from emp可求公司平均薪金 select ename,sal*12 from emp where sal*12>(select avg(sal*12) from emp);
10.列出与“SCOTT”从事相同工作的所有员工。
-- 可求出结果,但是表中也会有“SCOTT”对应的一行数据???,再加一个判断 select * from (select * from emp) t1 join (select job from emp where ename="SCOTT") t2 on t1.job=t2.job and ename!='SCOTT';
11.列出薪水等于部门30中员工的薪水的所有员工的姓名和薪水。
-- 部门30中员工的薪水都与别的部门的人的薪水不同,故只能求出部门30中人员的薪水和姓名 select ename,sal from emp where dept_no=30; -- 正常求解 select * from emp where sal in (select sal from emp where dept_no=30) and dept_no!=30;
12.列出薪金高于在部门30工作的所有员工的薪金的员工姓名和薪金。
-- 注: 聚合函数max()的使用 select ename,sal from emp where sal>(select max(sal) from emp where dept_no=30);
13.列出在每个部门工作的员工数量、平均工资和平均服务期限。
-- 平均服务期限 avg(datediff(current_date(),HIREDATE)) select count(ename),avg(sal),avg(datediff(current_date(),hire_date)) from emp group by dept_no;
14.列出所有员工的姓名、部门名称和工资。
select t1.ename,t2.dept_name,t1.sal from (select * from emp) t1 join -- 注:对第二张表进行处理,因为第二张表中名为ACCOUNTING的部门对应着两行数据,只取其中的一行即可(没有设计到部门地址的信息) -- 法二:select distinct(去重)dept_no,dept_name from dept (select dept_no,dept_name from dept group by dept_no,dept_name) t2 on t1.dept_no=t2.dept_no;
15.列出所有部门的详细信息和部门人数。
-- ACCOUNTING有两个地址 select t2.*,t1.counts from (select dept_no,count(ename) as counts from emp group by dept_no) t1 -- 右表中有一个不对应,故此用right join right join (select * from dept) t2 on t1.dept_no =t2.dept_no;
16.列出各种工作的最低工资。
-- 分组之后使用民()聚合函数即可 select min(sal),job from emp group by job;
17.列出各个部门的MANAGER(经理)的最低薪金。
-- 薪金 = 12*SAL加奖金 select *,12*sal+bonus as money from emp where job='MANAGER' order by 12*sal+bonus ASC limit 1;
18.列出所有员工的年工资,按年薪从低到高排序。
-- 年工资 = 年薪 = 12*SAL -- 降序DESC,升序ASC select ename,12*sal as money from emp order by 12*sal ASC;
19. 列出每个部门薪水前两名最高的人员名称以及薪水。
-- 法一: 经降序排序的每个部门小组的前两个人员???,无法实现取出每个部门薪水前两名最高的人员 select tt1.ename,tt1.sal,tt1.dept_name from (select t1.*,t2.dept_name from (select * from emp) t1 join -- 注:下面判断用到的数据必须经由select搜找之后才能用,不然下面的语句无法获得其值来进行判(t1.dept_no=t2.dept_no) (select dept_name,dept_no from dept group by dept_name,dept_no) t2 on t1.dept_no=t2.dept_no) tt1 ORDER BY dept_name,sal DESC; -- 法二: 使用union进行联合, 无需在最外层载打一个括号 select * FROM (select dept_no,sal from emp group by dept_no,sal having dept_no=10 order by sal desc limit 2) t1 UNION (select dept_no,sal from emp group by dept_no,sal having dept_no=20 order by sal desc limit 2) UNION (select dept_no,sal from emp group by dept_no,sal having dept_no=30 order by sal desc limit 2)20. 列出每个员工从受雇开始到2018-12-12 为止共受雇了多少天。
-- DATEDIFF(datepart,startdate,enddate) -- datepart 日期格式 -- startdate:开始日期 格式为合法的日期表达式 -- enddate:结束日期 格式为合法的日期表达式 select ename,datediff('2018-12-12',hire_date) as days from emp;
- 部门数据:
- 员工数据:


")
,部署WEB前后端项目步骤")




还没有评论,来说两句吧...